I recently found out about Is Your Site Agent Ready, a website by CloudFlare that tells you how much your website is indeed... agent ready.
"How cool is that?" I thought. Then something kicked in. I use LLMs and agents daily and they can indeed read HTML so I decided to go down the rabbit hole to have a better understanding about what being agent ready really means. For them at least.
I look up at the homepage, easy to read "What do we check?", "What's the easiest way to improve my score?" and "Where can I learn more?". There's plenty of stuff BUT my eyes drift to a small text at the bottom "These are AI-generated recommendations. AI can make mistakes. Please use your professional judgment when implementing these tips...".
Just as a recap: this is an AI website to check if your website is "AI ready" and since it's AI-generated you shouldn't fully trust it? Oh dear, I love AI but what about some HI (Human Intelligence) more?
Baseline
But as a SW engineer I can't stop there, I should know more, I should measure, I should set up an experiment to have a better understanding and get to appropriate conclusions.
I'll be doing the whole experiment using obviously this website: Kalizi.dev. It's behind CloudFlare so they already have it: archived, copied, stored, cached, versioned. They know it, they've seen each version of it. And they obviously know if any agent read it over time. Spoiler: Google, Amazon, Anthropic, OpenAI, Microsoft, ByteDance and Huawei did. I'm flattered. Next time I'd like a coffee at least.
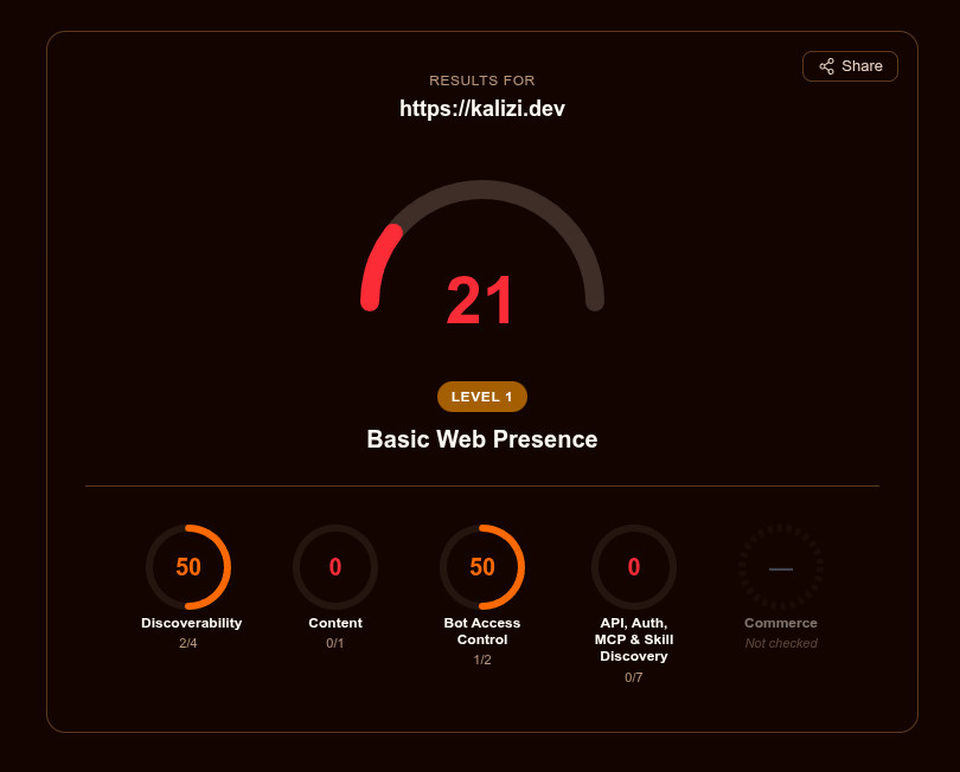
Anyway, I got a baseline evaluation of 21 out of 100: they say it's "Basic Web Presence" (Level 1).
Basic Web Presence
The score is weighted on 5 sections:
- Discoverability: 50 (2 out of 4)
- Content: 0 (0 out of 1)
- Bot Access Control: 50 (1 out of 2)
- API, Auth, MCP & Skill Discovery: 0 (0 out of 7)
- Commerce: not checked (this isn't an ecommerce website)
But there was still an idea spinning in my mind. Let's stop a moment and think what an AI agent is. Right now, when someone talks about an AI Agent it usually refers to empowering an LLM the capabilities to perform jobs and use tools inside a loop.
If we destructure an agent to its basic components, we have a series of messages and tools wrapped in a loop that goes on until the LLM chooses it's done. Something like this if you wanna put it technical:
messages = [
{"role": "user", "content": input()}
]
task_complete = False
while not task_complete:
response = llm(messages)
task_complete = response.task_complete
if response.should_call_tool:
tool_result = call_tool(
name=response.tool_name,
args=response.tool_args
)
messages.append({
"role": "assistant",
"content": response.reasoning_or_request
})
messages.append({
"role": "tool",
"content": tool_result
})
else:
output = response.output
messages.append({
"role": "assistant",
"content": output
})
print(output)Meaning the core is STILL the LLM.
Can an LLM read this website?
Most of the frontier LLMs are already agents, meaning they don't just give you an answer but they can use tools and perform tasks on your behalf. So I asked them, using the same prompt if they can read this website.
ChatGPT
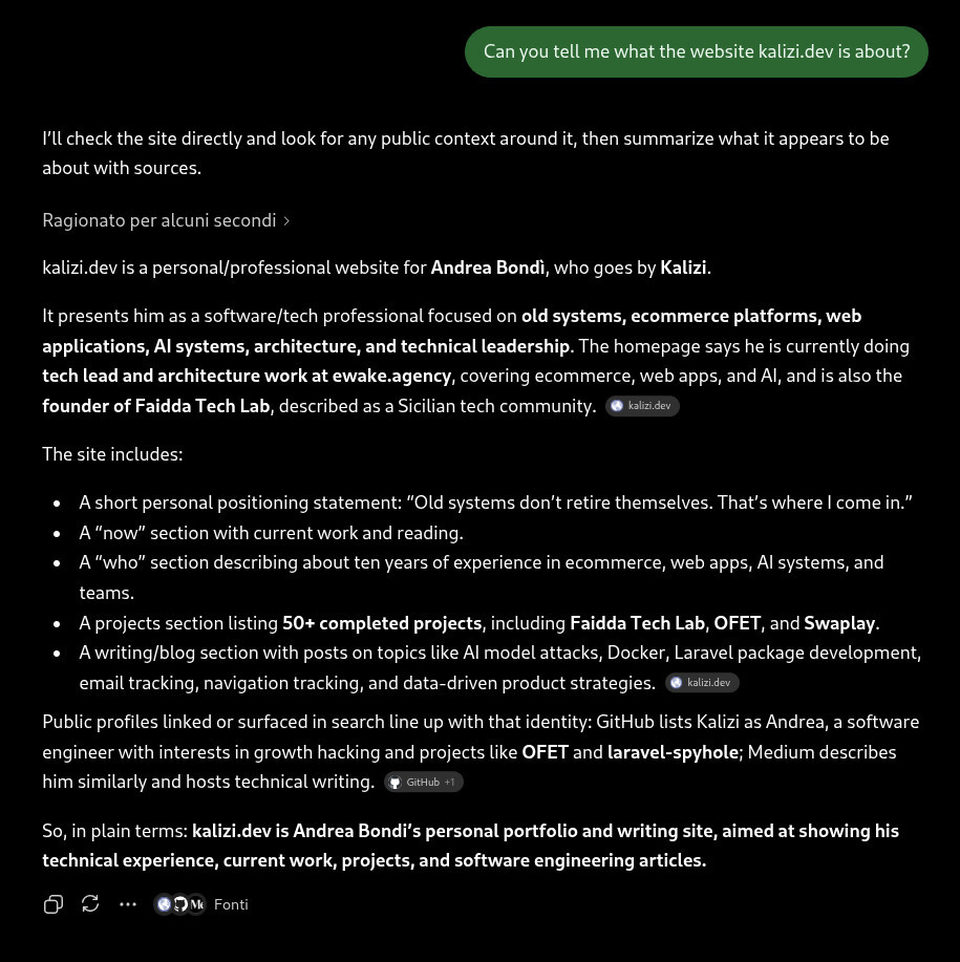
It seems ChatGPT can read it.
Claude
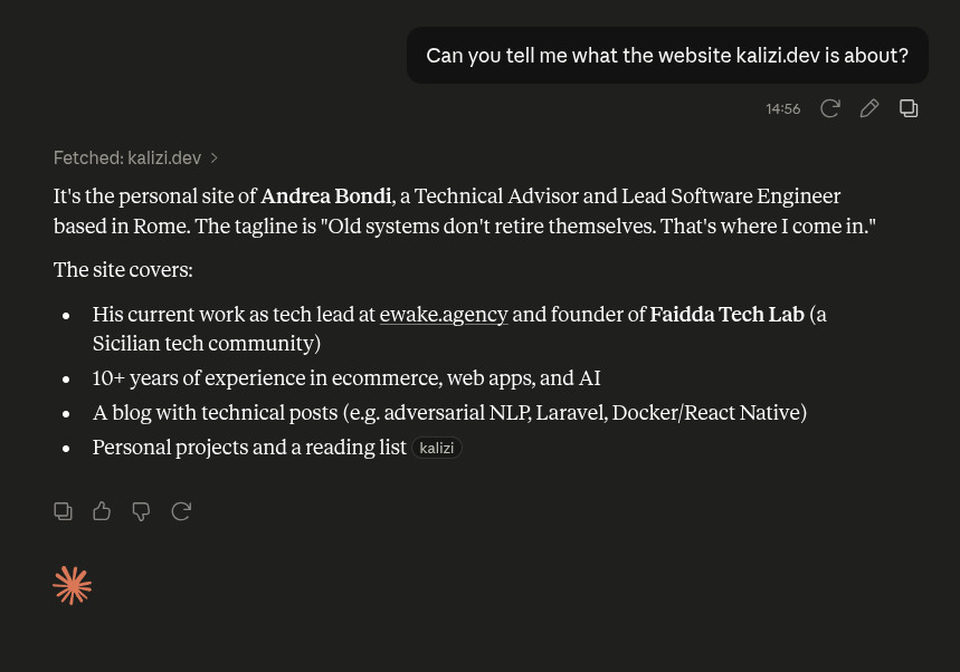
Claude can too.
Gemini
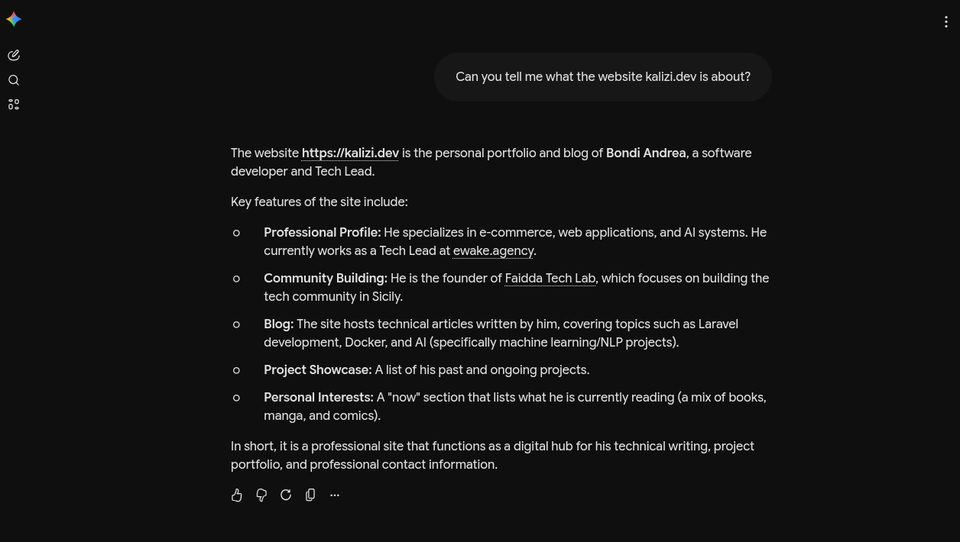
Gemini does it too.
Let's try something less "corporate".
Deepseek
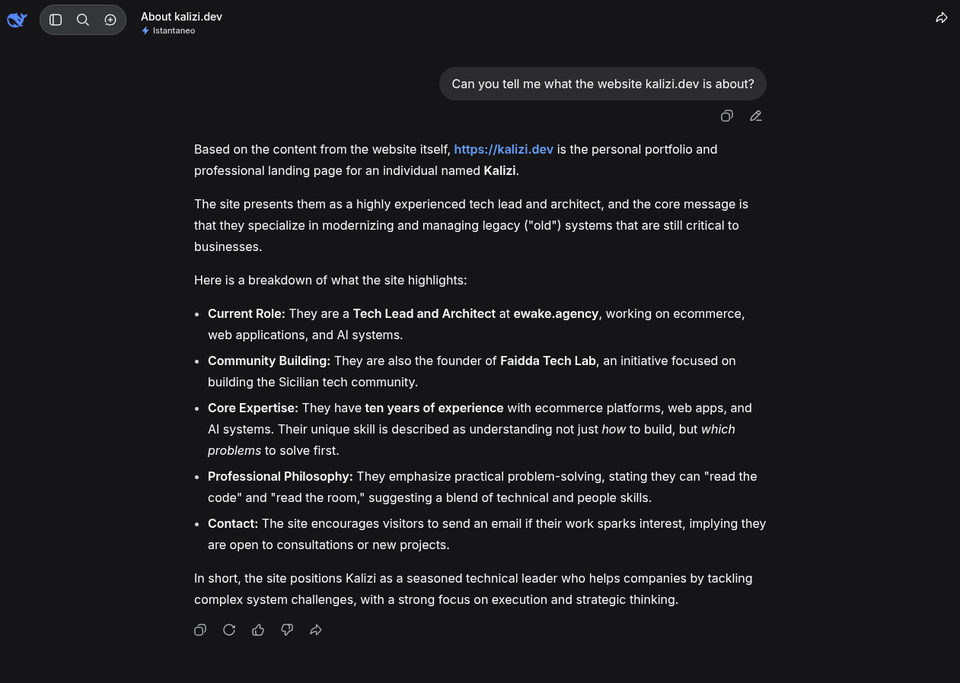
Deepseek appears to be reading the content too.
Mistral
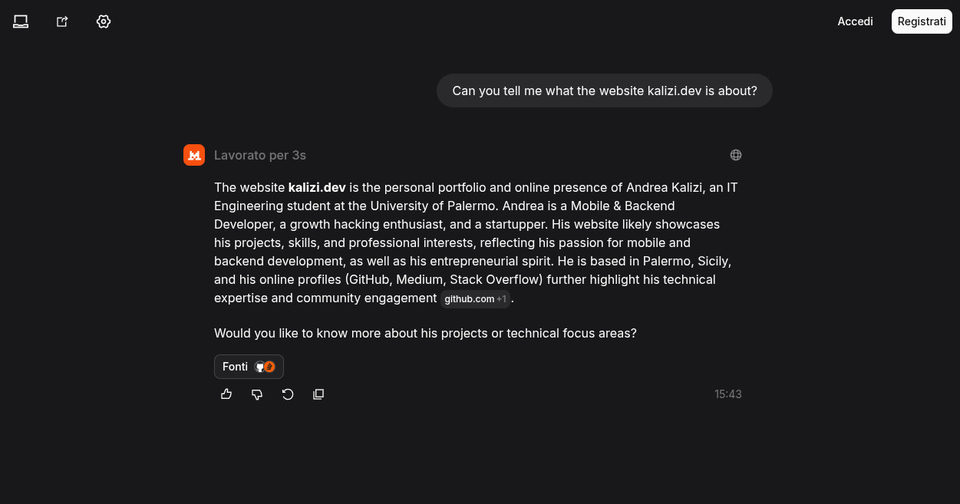
Even Mistral read this.
· · ·
Every single one of them.
So five different LLMs, from the big corporate ones to the scrappier open-source alternatives, all read and understood this website. Zero special configuration. No headers, no markdown negotiation, no DNS records. Just HTML.
Which raises the obvious question: if agents can already read the site just fine, what exactly was I scoring 21 out of 100 on?
So what do those scores mean?
Let's unpack them.
Discoverability
This score has 4 checks:
robots.txtSitemapLink headersDNS for AI Discovery (DNS-AID)
The robots.txt stated goal is: Publish /robots.txt with clear crawl rules.
User-agent: *
Disallow:
Allow: /
Sitemap: https://kalizi.dev/sitemap.xmlI see literally nothing specific for agents.
Publish a sitemap and reference it from robots.txt. Again, nothing you wouldn't do normally.
Link Headers is the first this website isn't ready. Goal: Include Link response headers for agent discovery (RFC 8288). The RFC is 48 printable pages long, it has 7 chapters and 3 appendixes. In short it states that when your server sends a page, it should include one or more Link: ... HTTP header that tell AI agents, or other software where to find machine-readable resources about your site or API.
So server should send something like:
Link: </me>; rel="author"
Link: </projects>; rel="collection"
Link: </blog>; rel="collection"Later on, HTML standard included their way to do it so there should also be something like:
<link rel="me" href="https://github.com/kalizi">
<link rel="me" href="https://www.linkedin.com/in/kalizi-dev/">Now let's take a look at DNS-AID before telling more. Goal: Publish DNS for AI Discovery (DNS-AID) records for DNS-based agent discovery. They refers RFC 9460. Another 48 pages.
This time it tells to add a new SVCB DNS Record to give browsers extra instructions so website loads faster. You can tell:
- use this subdomain
example.com. HTTPS 0 svc.example.net.- use this non-standard port
example.com. HTTPS 1 . port=8443- check this IP addresses
example.com. HTTPS 1 . ipv4hint=192.0.2.10 ipv6hint=2001:db8::10So...
Since the website is behind Cloudflare I can use nothing on the SVCB since I risk breaking cloudflare config about caching or HTTPs or leaking the IP (not that it really matters, it can be leaked many other ways but why use the proxy if I should hint the IP?). And do we really need links? I mean it may be faster for some software but is it for an agent? Agents and LLMs are meant to be smart, they know what they're seeking for and they may also skip the links.
Content
There's only 1 key point here: Markdown Negotiation. Goal: Return HTML responses as markdown when agents request it. This comes directly from Cloudflare docs and NOT from an RFC.
This point is someway controversial since it's just a proposal, there's no specific evidence about Accept: text/markdown is used by any agent, except from Cloudflare observations.
Even OpenCode has an open issue about this but this isn't implemented yet.
Markdown is a great format, very useful and I use it a lot with agents and even if it may help the LLMs, they may focus on the HTML to check other stuff like hidden elements, links and embedded data like JSON payloads and stuff.
Bot Access Control
Here we have "Bot Access Control". Goal: Add User-agent rules for AI crawlers like GPTBot, Claude-Web, and others. The fun part is reading the result No AI-specific bot rules; wildcard rules apply to all crawlers including AI bots. Okay!
Next is "Web Bot Auth request signing". I host no bots. Skip.
Last is curious, its goal states Declare AI content usage preferences with Content Signals in robots.txt.
PREFERENCES.
Here's an example Cloudflare gives:
Content-Signal: ai-train=no, search=yes, ai-input=noIt's just a preference, not an enforcing so... may I say I think it's useless?
API, Auth, MCP & Skill Discovery
We can talk a lot about this section. But shortly this website exposes no API, no authentication, no specific features so this is all useless for this specific purpose.
Agent Ready for What?
Here's the thing: all those LLMs read this website just fine. No special headers, no markdown negotiation, no DNS-AID records. They parsed the HTML, understood the content, answered questions about it.
So why the 21/100?
Because "agent ready" isn't really about readability. It's about actionability. There's a difference and it matters.
An LLM reading your website is a passive operation: fetch, parse, understand. Modern LLMs are very good at this. Readable HTML is enough for that.
"Agent ready" in Cloudflare's framing means something else entirely: can an AI agent do things on your website? Can it authenticate, call an API, invoke a skill, place an order? That's a completely different question.
For a blog like this one, the answer is: there's nothing to do. There are no actions to take. An agent can read about my projects but it can't fork one, book a call, or buy anything. That's not a failure, that's just what this website is.
The score of 21/100 isn't saying my site is invisible to agents. It's saying my site exposes no machine-actionable surface. Which is accurate.
So the real question isn't "is your site agent ready?" but "what do you want agents to actually do on your site?"
If the answer is "just read it": you're already there. Every LLM I tested did it without any special setup.
If you want agents to interact, transact, or integrate: yes, you have work to do. APIs, auth flows, MCP endpoints, the whole stack.
For most personal blogs and informational websites, this whole framework is solving a problem that doesn't exist yet. The LLMs can read your HTML. They've been doing it for years.
What Cloudflare is actually measuring is closer to API maturity for autonomous systems: a legitimate concern for e-commerce, SaaS platforms, service APIs. For a blog? It's a hammer looking for a nail.
21/100. Fine with it.