Ho scoperto di recente Is Your Site Agent Ready, un sito di CloudFlare che ti dice quanto il tuo sito sia davvero... agent ready.
"Che figata", ho pensato. Poi qualcosa ha preso il sopravvento. Uso LLM e agenti ogni giorno e sanno leggere HTML, quindi ho deciso di andare a fondo per capire meglio cosa significhi davvero essere agent ready. Per loro, almeno.
Apro la homepage: "What do we check?", "What's the easiest way to improve my score?", "Where can I learn more?". C'è roba, facile da leggere. MA i miei occhi cadono su un piccolo testo in fondo: "These are AI-generated recommendations. AI can make mistakes. Please use your professional judgment when implementing these tips...".
Ricapitoliamo: questo è un sito AI per verificare se il tuo sito è "AI ready" e, siccome le raccomandazioni sono generate dall'AI, non dovresti fidarti ciecamente? Adoro l'intelligenza artificiale, ma un po' di HI (Human Intelligence) in più non guasterebbe.
Baseline
Da ingegnere SW non posso fermarmi qui: devo sapere di più, devo misurare, devo impostare un esperimento per capire meglio e arrivare a conclusioni appropriate.
Farò tutto l'esperimento usando ovviamente questo sito: Kalizi.dev. È dietro CloudFlare, quindi loro ce l'hanno già: archiviato, copiato, salvato, in cache, versionato. Lo conoscono, ne hanno visto ogni versione. E sanno ovviamente se qualche agente lo ha letto nel tempo. Spoiler: Google, Amazon, Anthropic, OpenAI, Microsoft, ByteDance e Huawei l'hanno fatto. Sono lusingato. La prossima volta mi aspetto almeno un caffè.
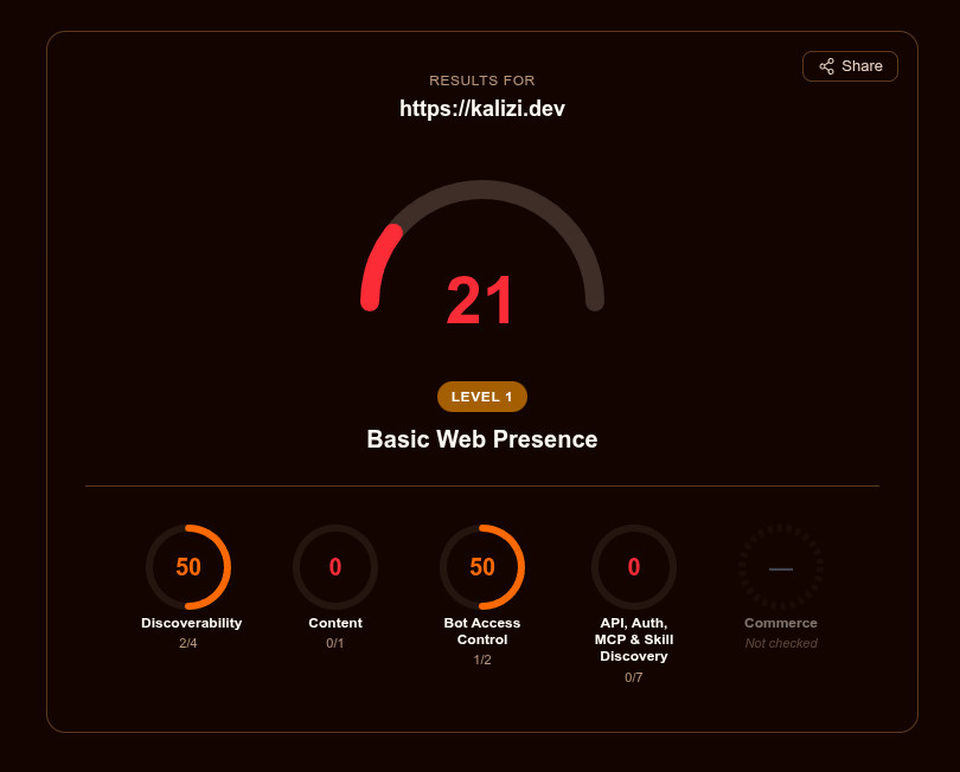
Comunque, ho ottenuto una valutazione di base di 21 su 100: dicono che è "Basic Web Presence" (Livello 1).
Basic Web Presence
Il punteggio è pesato su 5 sezioni:
- Discoverability: 50 (2 su 4)
- Content: 0 (0 su 1)
- Bot Access Control: 50 (1 su 2)
- API, Auth, MCP & Skill Discovery: 0 (0 su 7)
- Commerce: non verificato (questo non è un sito e-commerce)
Ma c'era ancora un'idea che girava in testa. Fermiamoci un momento e pensiamo a cos'è un agente AI. Oggi, quando si parla di AI Agent si intende generalmente potenziare un LLM con la capacità di svolgere compiti e usare strumenti in un loop.
Se decostruiamo un agente nei suoi componenti base, abbiamo una serie di messaggi e strumenti avvolti in un loop che continua finché l'LLM decide che ha finito. Qualcosa del genere, per chi vuole essere tecnico:
messages = [
{"role": "user", "content": input()}
]
task_complete = False
while not task_complete:
response = llm(messages)
task_complete = response.task_complete
if response.should_call_tool:
tool_result = call_tool(
name=response.tool_name,
args=response.tool_args
)
messages.append({
"role": "assistant",
"content": response.reasoning_or_request
})
messages.append({
"role": "tool",
"content": tool_result
})
else:
output = response.output
messages.append({
"role": "assistant",
"content": output
})
print(output)Il nucleo è SEMPRE l'LLM.
Un LLM può leggere questo sito?
La maggior parte degli LLM di frontiera sono già agenti: non ti danno solo una risposta ma possono usare strumenti e svolgere compiti per te. Quindi li ho interrogati tutti, con lo stesso prompt, per vedere se riuscivano a leggere questo sito.
ChatGPT
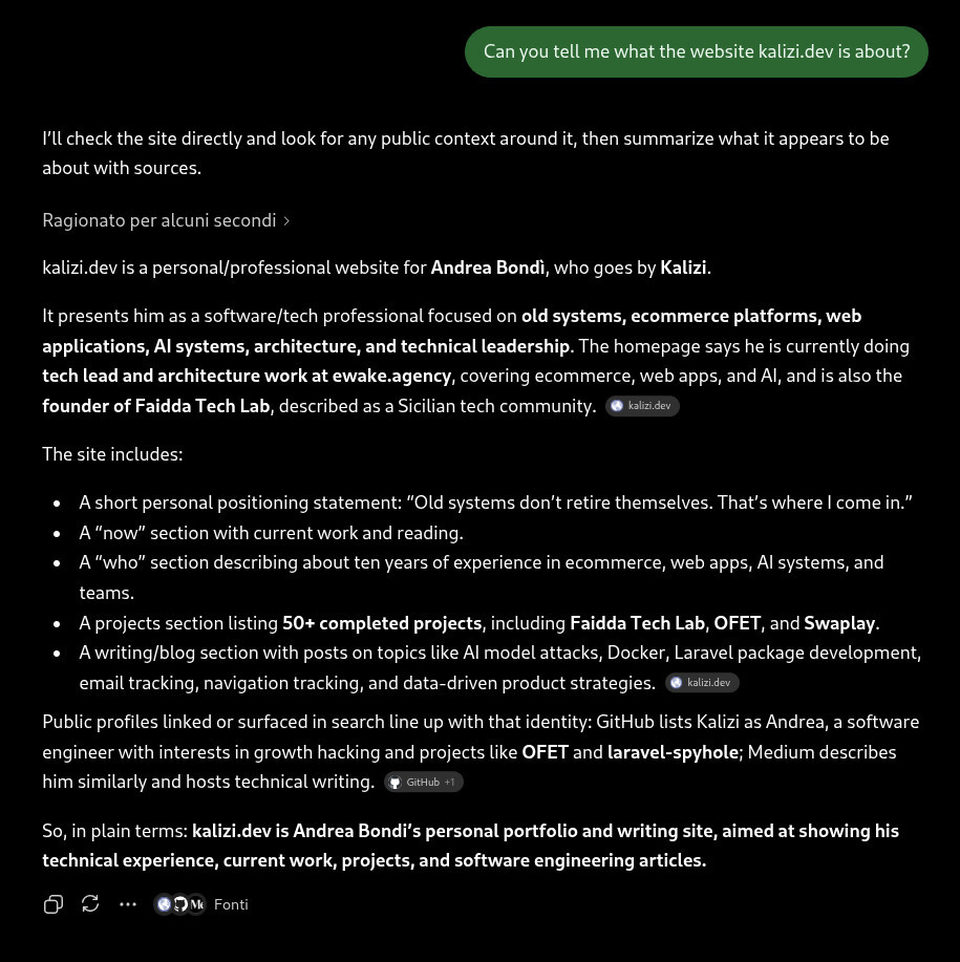
Sembra che ChatGPT ce la faccia.
Claude
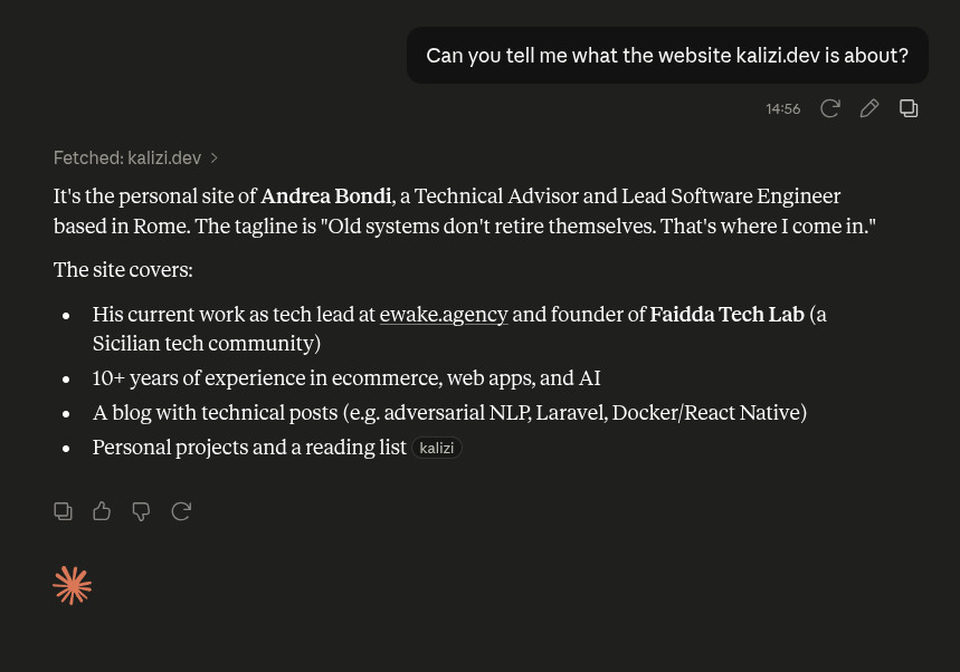
Anche Claude.
Gemini
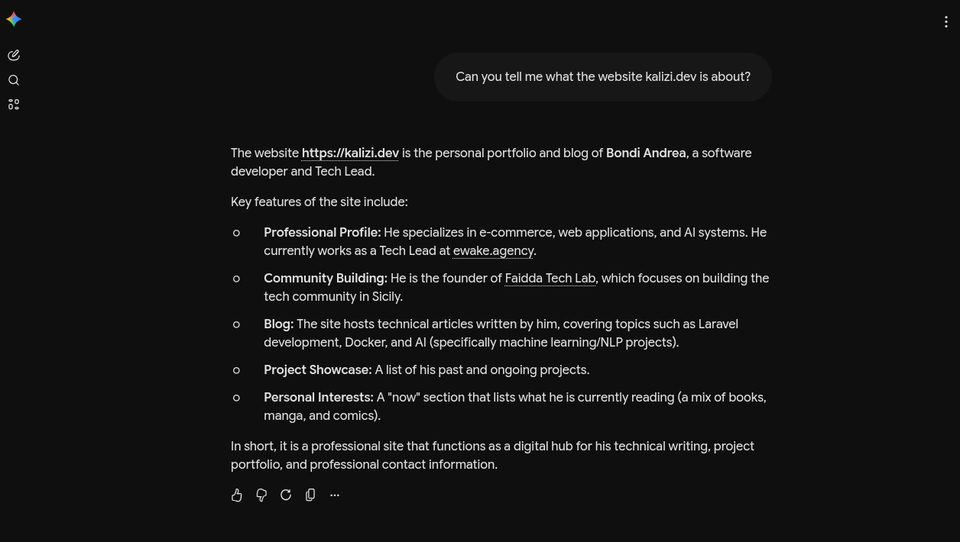
Pure Gemini.
Proviamo qualcosa di meno "corporate".
Deepseek
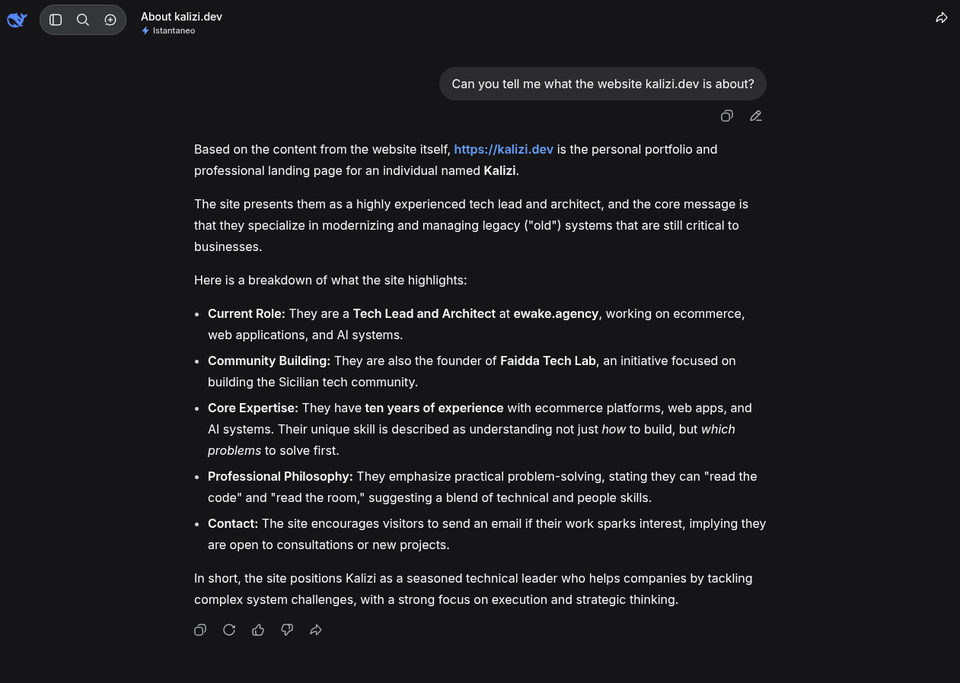
Anche Deepseek sembra leggere il contenuto.
Mistral
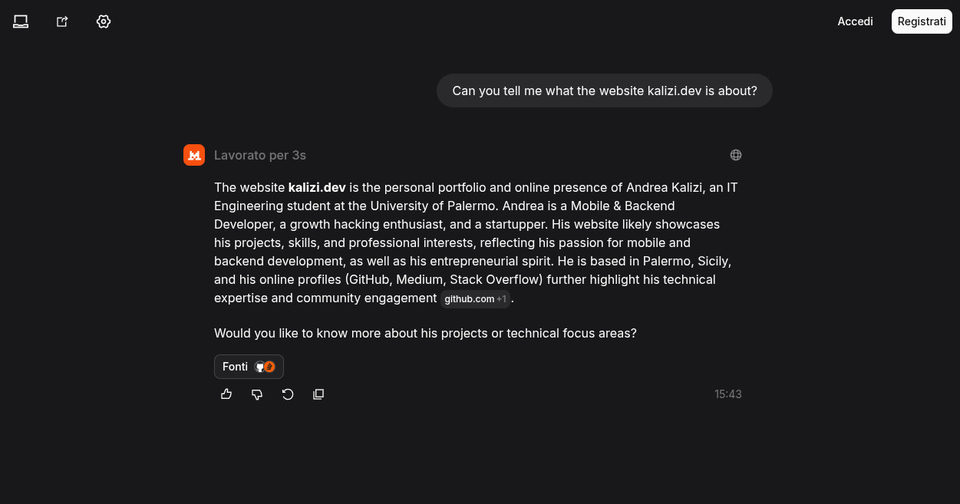
Persino Mistral l'ha letto.
· · ·
Proprio tutti.
Cinque LLM diversi, dai grandi nomi corporate alle alternative open-source più spigliate, hanno letto e capito questo sito. Zero configurazione speciale. Nessun header, nessuna markdown negotiation, nessun record DNS. Solo HTML.
Il che solleva la domanda ovvia: se gli agenti riescono già a leggere il sito senza problemi, su cosa stavo prendendo 21 su 100?
Allora cosa misurano questi punteggi?
Scomponiamoli.
Discoverability
Questo punteggio ha 4 controlli:
robots.txtSitemapLink headersDNS for AI Discovery (DNS-AID)
L'obiettivo dichiarato di robots.txt è: Pubblica /robots.txt con regole di crawl chiare.
User-agent: *
Disallow:
Allow: /
Sitemap: https://kalizi.dev/sitemap.xmlNon vedo letteralmente nulla di specifico per gli agenti.
Pubblica una sitemap e referenziala da robots.txt. Anche qui, niente che non faresti normalmente.
I Link Headers sono il primo punto su cui questo sito non è pronto. Obiettivo: Includi header HTTP Link per la scoperta degli agenti (RFC 8288). L'RFC è lungo 48 pagine stampabili, ha 7 capitoli e 3 appendici. In breve: quando il server invia una pagina, dovrebbe includere uno o più header HTTP Link: ... che indicano ad agenti AI, o ad altri software, dove trovare risorse leggibili dalla macchina sul tuo sito o API.
Quindi il server dovrebbe mandare qualcosa del tipo:
Link: </me>; rel="author"
Link: </projects>; rel="collection"
Link: </blog>; rel="collection"In seguito, lo standard HTML ha introdotto il suo modo di farlo, quindi dovrebbe esserci anche qualcosa come:
<link rel="me" href="https://github.com/kalizi">
<link rel="me" href="https://www.linkedin.com/in/kalizi-dev/">Diamo un'occhiata al DNS-AID prima di andare avanti. Obiettivo: Pubblica record DNS for AI Discovery (DNS-AID) per la scoperta degli agenti tramite DNS. Si riferisce all'RFC 9460. Altre 48 pagine.
Questa volta dice di aggiungere un nuovo record DNS SVCB per dare ai browser istruzioni extra e velocizzare il caricamento del sito. Puoi indicare:
- usa questo sottodominio
example.com. HTTPS 0 svc.example.net.- usa questa porta non standard
example.com. HTTPS 1 . port=8443- controlla questi indirizzi IP
example.com. HTTPS 1 . ipv4hint=192.0.2.10 ipv6hint=2001:db8::10Quindi...
Siccome il sito è dietro Cloudflare, non posso toccare nulla nell'SVCB senza rischiare di rompere la configurazione di caching o HTTPS di Cloudflare, o di esporre l'IP (non che sia un dramma, ci sono mille altri modi per trovarlo, ma a che serve il proxy se poi suggerisco l'IP direttamente?). E abbiamo davvero bisogno dei link? Può essere più veloce per qualche software, ma lo è per un agente? Gli agenti e gli LLM sono progettati per essere intelligenti, sanno cosa stanno cercando e possono tranquillamente ignorare i link.
Content
Qui c'è un solo punto chiave: la Markdown Negotiation. Obiettivo: Restituire le risposte HTML in markdown quando gli agenti lo richiedono. Viene direttamente dalla documentazione di Cloudflare e NON da un RFC.
Questo punto è in qualche modo controverso: è solo una proposta, non ci sono prove specifiche che Accept: text/markdown venga usato da qualche agente, tranne nelle osservazioni di Cloudflare.
Anche OpenCode ha una issue aperta sull'argomento, ma non è ancora implementata.
Il markdown è un formato fantastico, lo uso moltissimo con gli agenti, e anche se potrebbe aiutare gli LLM, potrebbero comunque preferire l'HTML per verificare altri elementi: tag nascosti, link, dati embedded come payload JSON e simili.
Bot Access Control
Qui abbiamo il "Bot Access Control". Obiettivo: Aggiungi regole User-agent per i crawler AI come GPTBot, Claude-Web e altri. La parte divertente è leggere il risultato: No AI-specific bot rules; wildcard rules apply to all crawlers including AI bots. Ok!
Il punto successivo è la "Web Bot Auth request signing". Non gestisco bot. Saltato.
L'ultimo è curioso, il suo obiettivo recita Dichiara le preferenze di utilizzo dei contenuti AI con Content Signals nel robots.txt.
PREFERENZE.
Ecco un esempio di Cloudflare:
Content-Signal: ai-train=no, search=yes, ai-input=noÈ solo una preferenza, non un'imposizione, quindi... posso dire che la trovo inutile?
API, Auth, MCP & Skill Discovery
Si potrebbe parlare a lungo di questa sezione. Ma in breve: questo sito non espone API, non ha autenticazione, non ha funzionalità specifiche, quindi è tutto irrilevante per questo scopo.
Agent Ready per cosa?
Ecco il punto: tutti quegli LLM hanno letto questo sito senza problemi. Nessun header speciale, nessuna markdown negotiation, nessun record DNS-AID. Hanno analizzato l'HTML, capito il contenuto, risposto a domande su di esso.
Quindi perché 21/100?
Perché "agent ready" non riguarda davvero la leggibilità. Riguarda l'azionabilità. C'è una differenza, e conta.
Un LLM che legge il tuo sito è un'operazione passiva: fetch, parse, comprensione. Gli LLM moderni sono molto bravi in questo. L'HTML leggibile è sufficiente.
"Agent ready" nel senso di Cloudflare significa qualcosa di completamente diverso: un agente AI può fare cose sul tuo sito? Può autenticarsi, chiamare un'API, invocare una skill, piazzare un ordine? È una domanda completamente diversa.
Per un blog come questo, la risposta è: non c'è nulla da fare. Non ci sono azioni da compiere. Un agente può leggere dei miei progetti ma non può forkarne uno, prenotare una call o comprare qualcosa. Non è un fallimento, è semplicemente quello che è questo sito.
Il punteggio di 21/100 non dice che il mio sito è invisibile agli agenti. Dice che il mio sito non espone nessuna superficie azionabile dalla macchina. Il che è accurato.
Quindi la vera domanda non è "il tuo sito è agent ready?" ma "cosa vuoi che gli agenti facciano sul tuo sito?"
Se la risposta è "leggerlo e basta": ci sei già. Ogni LLM che ho testato l'ha fatto senza nessuna configurazione speciale.
Se vuoi che gli agenti interagiscano, transazionino o si integrino: sì, hai lavoro da fare. API, flussi di autenticazione, endpoint MCP, tutto lo stack.
Per la maggior parte dei blog personali e dei siti informativi, questo framework sta risolvendo un problema che non esiste ancora. Gli LLM possono leggere il tuo HTML. Lo fanno da anni.
Quello che Cloudflare sta davvero misurando è qualcosa di più vicino alla maturità API per sistemi autonomi: una preoccupazione legittima per e-commerce, piattaforme SaaS, API di servizio. Per un blog? È un martello in cerca di un chiodo.
21/100. Ci sto benissimo.